
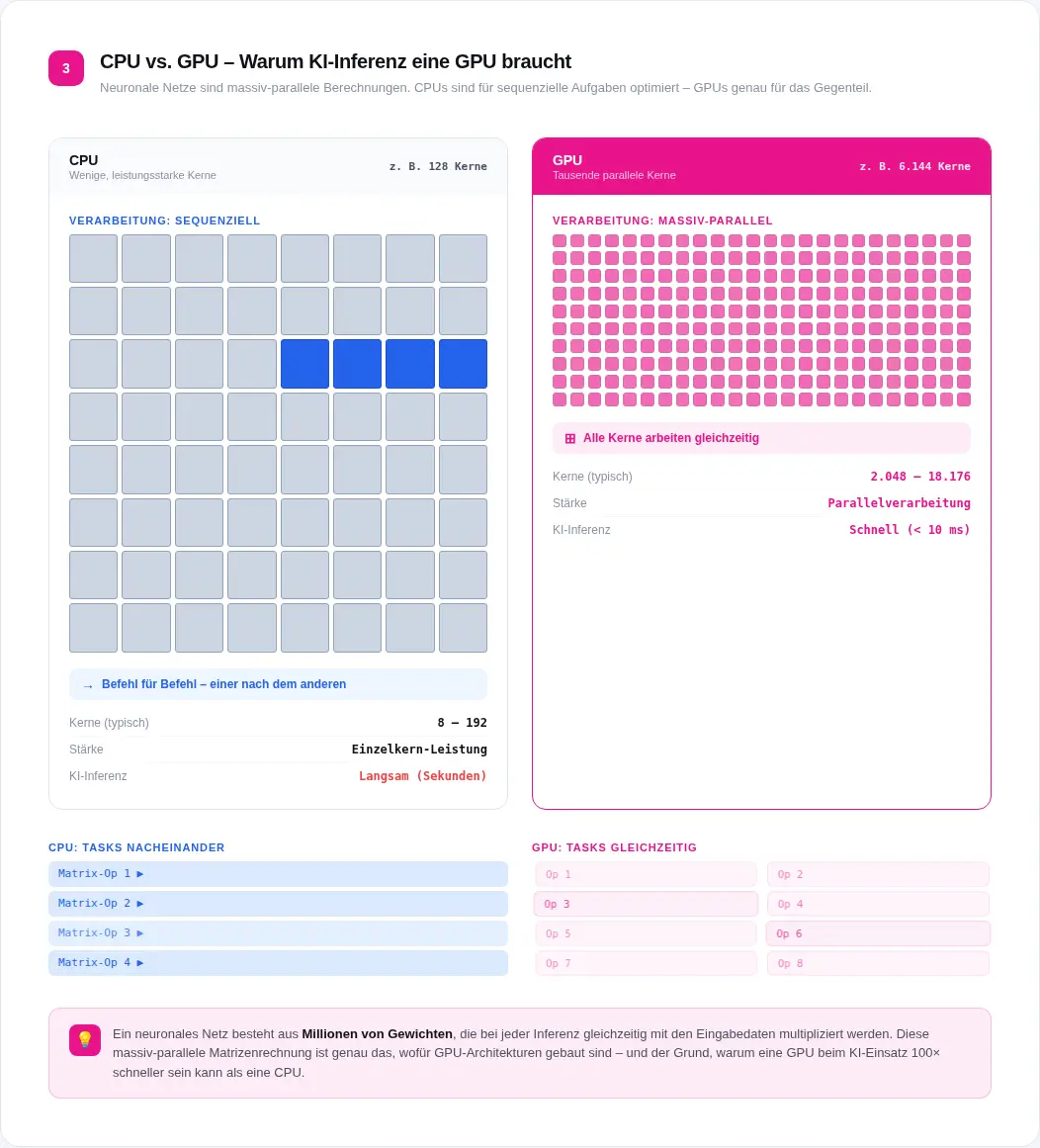
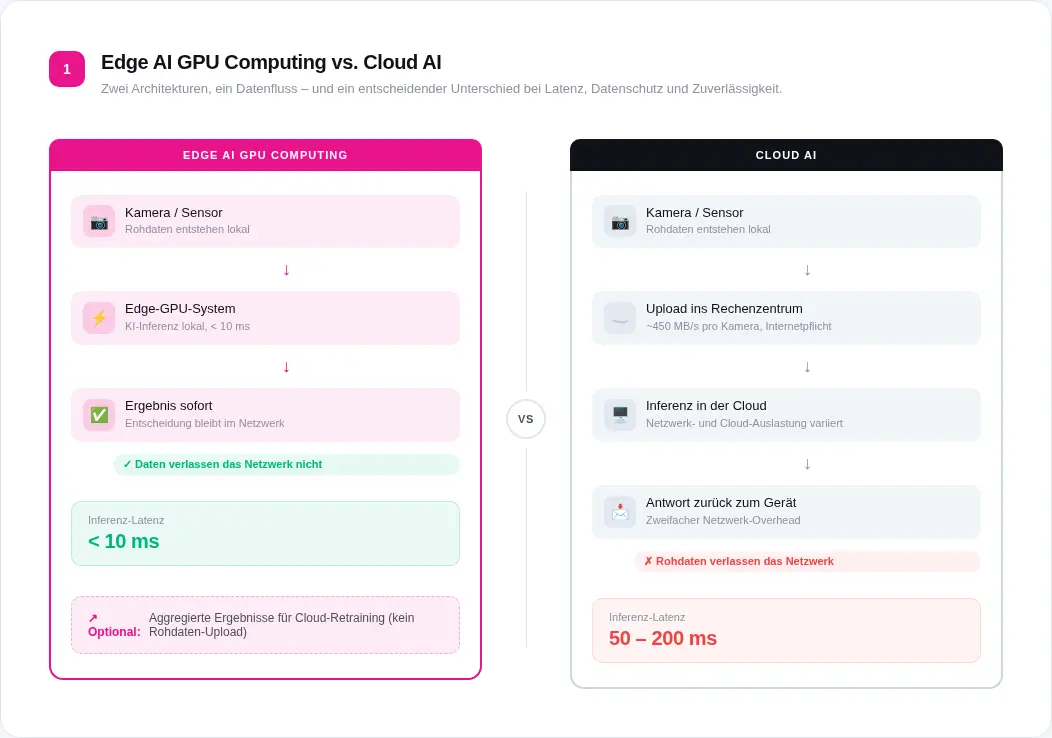
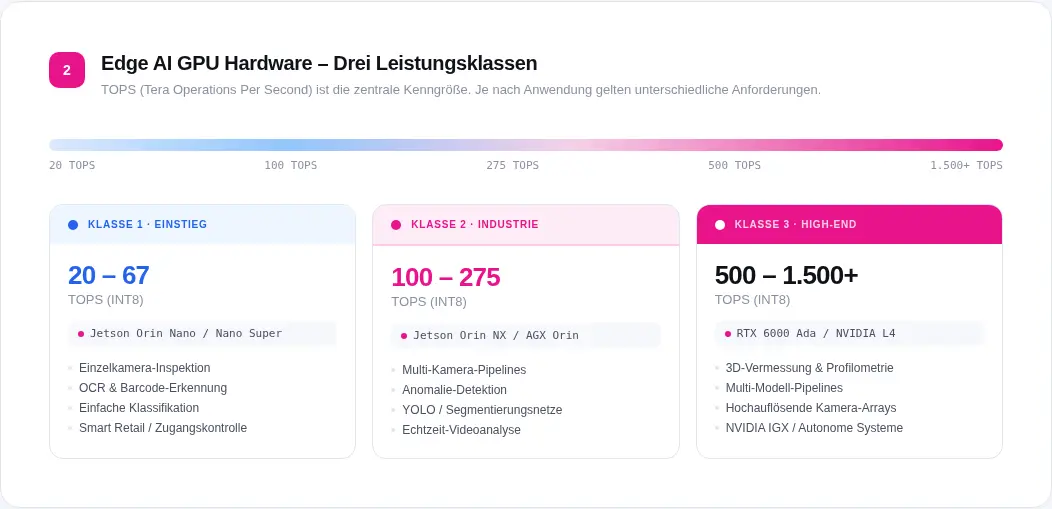

Das klassische Heimspiel. Produktionslinien mit Taktzeiten unter einer Sekunde, Inline-Prüfung von Bauteilen, Leiterplatten oder Oberflächen auf Kratzer, Lötstellen, Maßabweichungen, Verunreinigungen. Deep-Learning-Modelle erkennen auch Defektvarianten, die mit regelbasierten Algorithmen nicht erfassbar wären. GPU-beschleunigte Inferenz mit TensorRT liefert Ergebnisse, bevor das nächste Bauteil unter der Kamera liegt. Bei Taktzeiten unter einer Sekunde ist das keine Optimierung; das ist die Grundbedingung.






Das muss man gelesen haben?
Behalten Sie ihr Wissen nicht für sich und teilen Sie diesen Beitrag.